
I’ve always faced issues in my current ECS setup where the default scaling mechanism is not as “reactive” but rather proactive. Whether is it CPU utilization or load balancer hits, its not as efficient in dealing with unforeseen/volatile loads and end up wasting tons of money when load is gone.
I’ve hosted an application in AWS ECS backed by ASG EC2 , which uses CPU utilization but this scaling metrics is inefficient and expensive as my loads are volatile and by the time ECS managed to scale up, the load is gone. Also I do face issues in getting ECS to scale “faster” in a way that it would react based on incoming job loads rather than resource utilization. To add on, ECS has a limit of 300 tasks that could be in pending state so I’m determined to perform some “magic” to fix this problem!
All Hail! AWS Swiss Army Knife!
Reason why i picked lambda
- Perform custom calculation
- Can integrate quickly with almost all aspect of AWS without changing current design for future proofing
- Cheap ( hopefully free )
- Can perform API calls to internal LoadBalancer
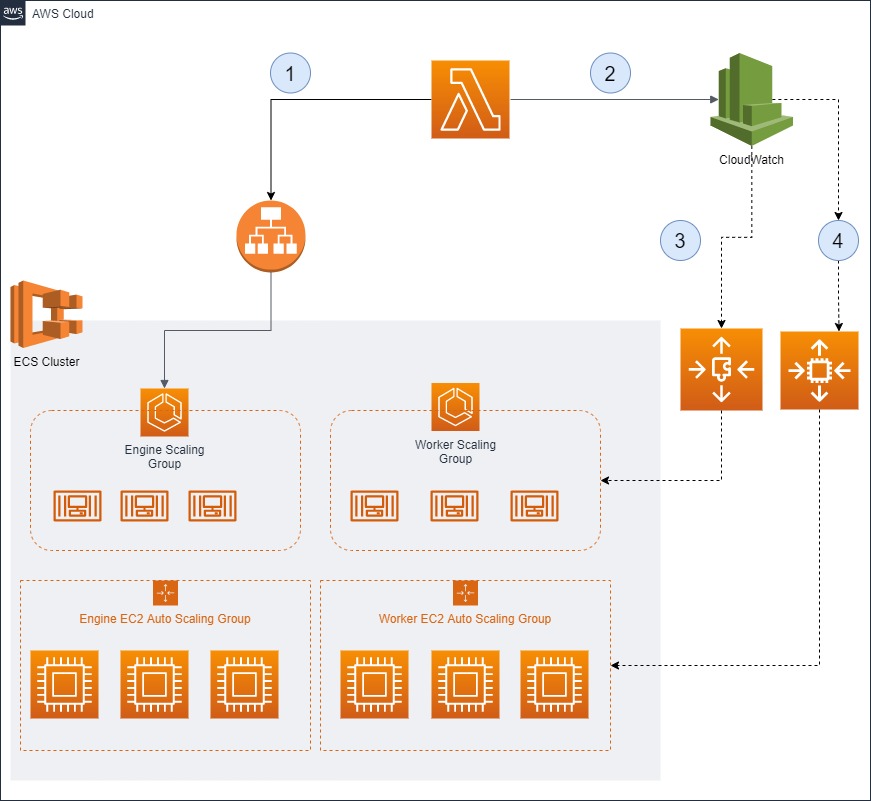
The following flow will illustrate the whole scaling flow
- Lambda will perform API calls to internal LoadBalancer to retrieve “Pending jobs” and “Current worker count”
- Calculate the ECS cluster’s “velocity” – Pending jobs / current worker count
- Calculate the EC2 cluster’s size “velocity” – (pending jobs / current worker count) / 300
- 300 is equivalent to 5mins which is an average time each job will take
- Note that by configuration, each ec2 can only host 8 worker tasks
- Lambda will post the custom metric to CW metric
- ECS tasks scaling policies are configured to use “Target Tracking Policy” and point to the custom metric.
- The threshold to be 300 as 300 equates to 5min which is our average time needed process a job
- EC2 Scaling policy, capacity provider was configured but to improve the scaling mechanism, what I’ve did was to reverse engineer how capacity provider works and manipulate the metric data such that it will pre-empt the ASG ec2 count and ready for ECS tasks to be deployed
- Post EC2 cluster velocity * 100 – capacity provider works by percentage
With this solution, the design was able to scale from 100 – 5000 ECS tasks in 3-5mins based on incoming load and it will scale down when load is gone. Where without lambda, it took nearly 40mins to do so!
Lambda utilization was not huge and was only scheduled to run by “Event bridge” every 1min so the cost involve is essentially FREE!!!!



{kind=link}